本文介紹了面向 AI 推理的英特爾® 精選解決方案以及其如何解決 AI 推理部署的痛點,包括其中(zhōng)采用的軟件、硬件和技術。該系列解決方案有基礎和增強配置,提供靈活的可定制性,以滿足不同需求。您可通過閱讀本文具體(tǐ)了解如何在符合行業标準的硬件上部署優化的高速人工(gōng)智能推理,驅動更高商(shāng)業價值。
越來越多的企業希望借助人工(gōng)智能 (AI) 以增加收入、提高效率并推動産品創新。尤其需要指出的是,基于深度學習 (DL) 技術的人工(gōng)智能用例能夠帶來有效且實用的洞察;其中(zhōng)一(yī)些用例可在衆多行業推動進步,例如:
這些用例僅僅隻是開(kāi)始。随着企業将人工(gōng)智能融入業務運營,他們将發現應用人工(gōng)智能的新方法。然而,所有人工(gōng)智能用例的商(shāng)業價值都取決于由深度神經網絡訓練的模型的推理速度。在深度學習模型上支持推理所需的資(zī)源規模可能非常龐大(dà),通常需要企業更新硬件以獲得其所需的性能和速度。但是,許多客戶希望擴展其現有的基礎設施,而不是重新購買單一(yī)用途的新硬件。您的 IT 部門已經非常熟悉英特爾® 硬件架構,其靈活性能使您的 IT 投資(zī)更高效。面向人工(gōng)智能推理的英特爾® 精選解決方案是“一(yī)站式”平台,提供經過預配置、優化和驗證的解決方案,無需另外(wài)配置加速卡,即可在 CPU 上實現低時延、高吞吐量的推理。
面向人工(gōng)智能推理的英特爾® 精選解決方案
面向人工(gōng)智能推理的英特爾® 精選解決方案能幫助您快速入門,利用基于經驗證的英特爾® 架構的解決方案,部署高效的人工(gōng)智能推理算法,從而加速創新和産品上市。爲了加快人工(gōng)智能應用的推理和上市,面向人工(gōng)智能推理的英特爾® 精選解決方案結合了多種英特爾及第三方的軟硬件技術。
軟件選擇
面向人工(gōng)智能推理的英特爾® 精選解決方案使用的軟件包括開(kāi)發人員(yuán)工(gōng)具和管理工(gōng)具,以輔助生(shēng)産環境中(zhōng)的人工(gōng)智能推理。
英特爾® 分(fēn)發版 OpenVINO™ 工(gōng)具包
英特爾® 分(fēn)發版開(kāi)放(fàng)視覺推理和神經網絡優化工(gōng)具包(即英特爾® 分(fēn)發版 OpenVINO™ 工(gōng)具包)是一(yī)套開(kāi)發人員(yuán)套件,可加速高性能人工(gōng)智能和深度學習推理的部署。該工(gōng)具套件可針對多種英特爾® 硬件選項,對各種不同框架訓練的模型進行優化,以提供出色性能部署。工(gōng)具套件中(zhōng)的深度學習工(gōng)作台 (DL Workbench) 可将模型量化到較低精度。在此過程中(zhōng),工(gōng)具套件把使用較大(dà)的高精度 32 位浮點數(通常用于訓練,會占用較多内存)的模型轉換爲 8 位整數,以優化内存使用和性能。将浮點數轉換爲整數能夠在保持幾乎相同精度的同時,顯著提高人工(gōng)智能推理速度1。該工(gōng)具套件可以轉換和執行在多種框架中(zhōng)構建的模型,包括 TensorFlow、MXNet、PyTorch、Kaldi 和開(kāi)放(fàng)神經網絡交換 (Open Neural Network Exchange, ONNX) 生(shēng)态系統所支持的任何框架。此外(wài),用戶還可獲得經過預訓練的公開(kāi)模型,無需再自行搜尋或訓練模型,從而加速基于英特爾® 處理器的開(kāi)發和圖像處理管道優化。
深度學習參考堆棧
面向人工(gōng)智能推理的英特爾® 精選解決方案配備深度學習參考堆棧 (DLRS)。這是一(yī)個集成的高性能開(kāi)源軟件堆棧,已針對英特爾® 至強® 可擴展處理器進行優化,并封裝在一(yī)個便捷的 Docker 容器中(zhōng)。DLRS 經過預先驗證,并且配置完善,已包含所需的庫和軟件組件,因此有助于降低人工(gōng)智能在生(shēng)産環境中(zhōng)與多個軟件組件集成所帶來的複雜(zá)性。該堆棧還包括針對主流深度學習框架 TensorFlow 和 PyTorch 高度調優的容器,以及英特爾® 分(fēn)發版 OpenVINO™ 工(gōng)具包。該開(kāi)源社區版本也有利于确保人工(gōng)智能開(kāi)發人員(yuán)可輕松獲得英特爾® 平台的所有特性和功能。
Kubeflow 和 Seldon Core
随着企業和機構不斷積累在生(shēng)産環境中(zhōng)部署推理模型的經驗,業界逐步形成了一(yī)系列最佳實踐的共識,即 “MLOps”,類似于 “DevOps” 軟件開(kāi)發實踐。爲了幫助團隊應用 MLOps,面向人工(gōng)智能推理的英特爾® 精選解決方案使用 Kubeflow。借助 Kubeflow,團隊可在“零停機”的情況下(xià)順利推出模型的新版本。Kubeflow 使用受到支持的模型服務後端(例如 TensorFlow Serving)将經過訓練的模型導出到 Kubernetes。模型部署則可使用金絲雀測試或影子部署來實現新舊(jiù)版本的并行驗證。如果發現問題,除了進行跟蹤,團隊還可以使用模型和數據版本控制來簡化根本原因分(fēn)析。
爲了在需求增加時保持快捷響應的服務,面向人工(gōng)智能推理的英特爾® 精選解決方案提供負載平衡功能,能夠跨節點将推理自動分(fēn)片到可服務對象的可用實例中(zhōng)。多租戶支持提供不同的模型,從而提高硬件利用率。最後,爲了在運行人工(gōng)智能推理的服務器和需要人工(gōng)智能洞察的端點之間加速處理推理請求,面向人工(gōng)智能推理的英特爾® 精選解決方案可以使用 Seldon Core 來幫助管理推理管道。Kubeflow 還與 Seldon Core 集成,從而在 Kubernetes 上部署深度學習模型,并使用 Kubernetes API 來管理部署在推理管道中(zhōng)的容器。
硬件選擇
面向人工(gōng)智能推理的英特爾® 精選解決方案結合了第二代英特爾® 至強® 可擴展處理器、英特爾® 傲騰™ 固态盤 (SSD)、英特爾® 3D NAND 固态盤和英特爾® 以太網 700 系列,因此您的企業可以在性能經過優化的平台上快速部署生(shēng)産級人工(gōng)智能基礎設施,爲要求嚴苛的應用和工(gōng)作負載提供大(dà)内存容量。
第二代英特爾® 至強® 可擴展處理器
面向人工(gōng)智能推理的英特爾® 精選解決方案具有第二代英特爾® 至強® 可擴展處理器的性能和功能。對于“基礎”配置,英特爾® 至強® 金牌 6248 處理器在價格、性能和集成技術之間實現了出色的平衡,能夠增強人工(gōng)智能模型上的推理性能與效率。“增強”配置則采用專爲實現更快人工(gōng)智能推理而設計的英特爾® 至強® 鉑金 8268 處理器。此外(wài),在任一(yī)配置中(zhōng)也可選用更高型号的處理器。第二代英特爾® 至強® 可擴展處理器包含英特爾® 深度學習加速技術。這是一(yī)系列加速功能,可通過專門的矢量神經網絡指令 (VNNI) 集來提高人工(gōng)智能推理性能。該指令集使用一(yī)條單獨指令即可完成之前需要三條單獨指令才能進行的深度學習計算。
英特爾® 傲騰™ 技術
英特爾® 傲騰™ 技術填補了存儲和内存層之間的重要空白(bái),讓數據中(zhōng)心能夠更快地獲取數據。這項技術颠覆了内存和存儲層,能夠在各種不同産品和解決方案中(zhōng)提供持久内存、大(dà)型内存池、高速緩存和存儲。
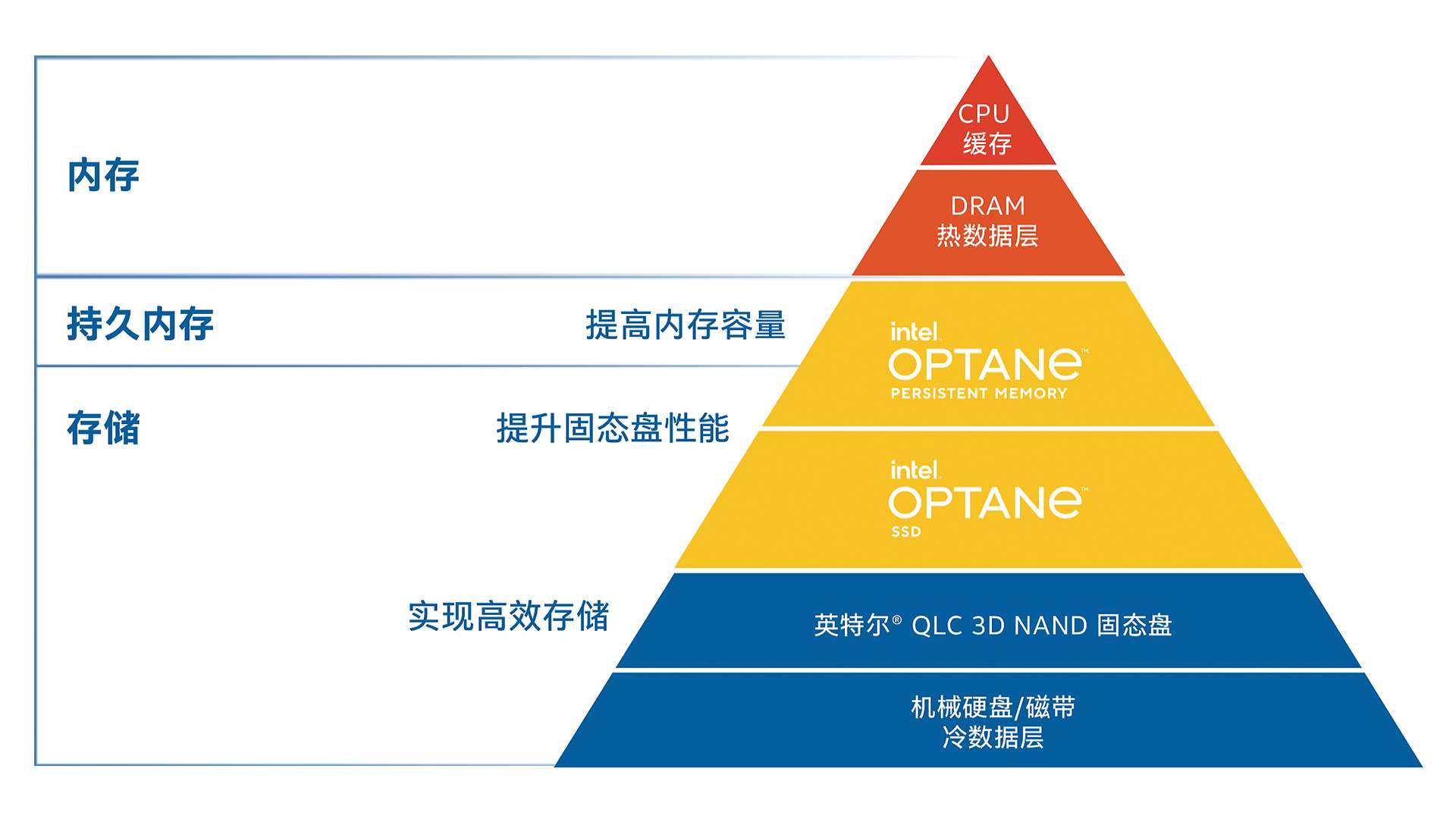
圖 1. 英特爾® 傲騰™ 技術填補了數據中(zhōng)心内存和存儲之間的性能空白(bái)
英特爾® 傲騰™ 固态盤和英特爾® 3D NAND 固态盤
當緩存層運行在具備低時延和高耐用性的高速固态盤上時,人工(gōng)智能推理更能充分(fēn)發揮其性能。如緩存層采用高性能固态盤而非主流串行 ATA (SATA) 固态盤,則要求高性能的工(gōng)作負載将受益匪淺。在英特爾® 精選解決方案中(zhōng),緩存層采用英特爾® 傲騰™ 固态盤。英特爾® 傲騰™ 固态盤單位成本可提供較高的每秒讀寫次數 (IOPS),且具備低時延和高耐用性,再加上高達 30 次的每日整盤寫入次數 (DWPD),是寫入密集型緩存功能的理想選擇2。容量層則采用英特爾® 3D NAND 固态盤,可提供出色的讀取性能,并兼具數據完整性、性能一(yī)緻性和驅動可靠性。
25 Gb 以太網
25 Gb 英特爾® 以太網 700 系列網絡适配器能夠提升面向人工(gōng)智能推理的英特爾® 精選解決方案的性能。與使用 1 Gb 以太網 (GbE) 适配器和英特爾® 固态盤 DC S4500 相比,使用 25 Gb 以太網适配器配合第二代英特爾® 至強® 鉑金處理器和英特爾® 固态盤 DC P4600 可提供高達前者 2.5 倍的性能34。英特爾® 以太網 700 系列提供經過驗證的性能;其廣泛的互操作性可在數據彈性和服務可靠性方面滿足高質量阈值5。所有英特爾® 以太網産品均提供全球售前和售後支持,并在産品周期内提供有限質保。
經過基準測試驗證的性能
所有英特爾® 精選解決方案均通過基準測試驗證,已滿足預先指定的工(gōng)作負載優化性能的最低功能級别。在數據中(zhōng)心、網絡邊緣和雲中(zhōng)的各類工(gōng)作負載中(zhōng),人工(gōng)智能推理正逐漸成爲其重要組成部分(fēn),因此英特爾選擇使用标準的深度學習基準測試方法,并模拟真實場景進行測量和基準測試。
在标準基準測試中(zhōng),每秒可處理的圖像數量(即吞吐量)是在一(yī)個經過預先訓練的深度殘差神經網絡 (ResNet 50 v1) 上測量的。該神經網絡與使用合成數據的 TensorFlow、PyTorch 和 OpenVINO™ 工(gōng)具套件上廣泛使用的深度學習用例(如圖像分(fēn)類、定位和檢測)密切相關。
爲了模拟真實場景,測試啓動了多個客戶端,以模拟多個請求流。這些客戶端将圖像從外(wài)部客戶端系統發送到服務器以進行推理。在服務器端,入站請求由 Istio 進行負載平衡。然後,請求将發送到一(yī)個可服務對象的多個實例,該對象包含通過 Seldon Core 運行的一(yī)條預處理、預測和後處理步驟管道。預測使用 OpenVINO™ 工(gōng)具包中(zhōng) Model Server 經過優化的 DLRS 容器映像完成。在請求通過管道後,推理結果将返回給提出請求的客戶端。在此過程中(zhōng)測量出的吞吐量和時延可幫助确保此測試配置足以支持生(shēng)産環境中(zhōng)的推理規模。
基礎配置和增強配置
我(wǒ)(wǒ)們以兩種參考配置(“基礎配置”和“增強配置”)向您展示面向人工(gōng)智能推理的英特爾® 精選解決方案。兩者均已經過驗證,可提供出色性能。這兩種配置經過專門的設計和預測試,可提供出衆的價值、性能、安全性和用戶體(tǐ)驗。最終客戶也可與系統構建商(shāng)、系統集成商(shāng),或是解決方案和服務提供商(shāng)合作,根據企業和機構的需求與預算來定制這些配置。
“基礎配置”具有出色的性價比,且已針對人工(gōng)智能推理工(gōng)作負載進行優化。“增強配置”使用高于“基礎配置”的英特爾® 至強® 可擴展處理器型号,并增加一(yī)倍内存。表 1 列出了這兩種配置的詳細信息。
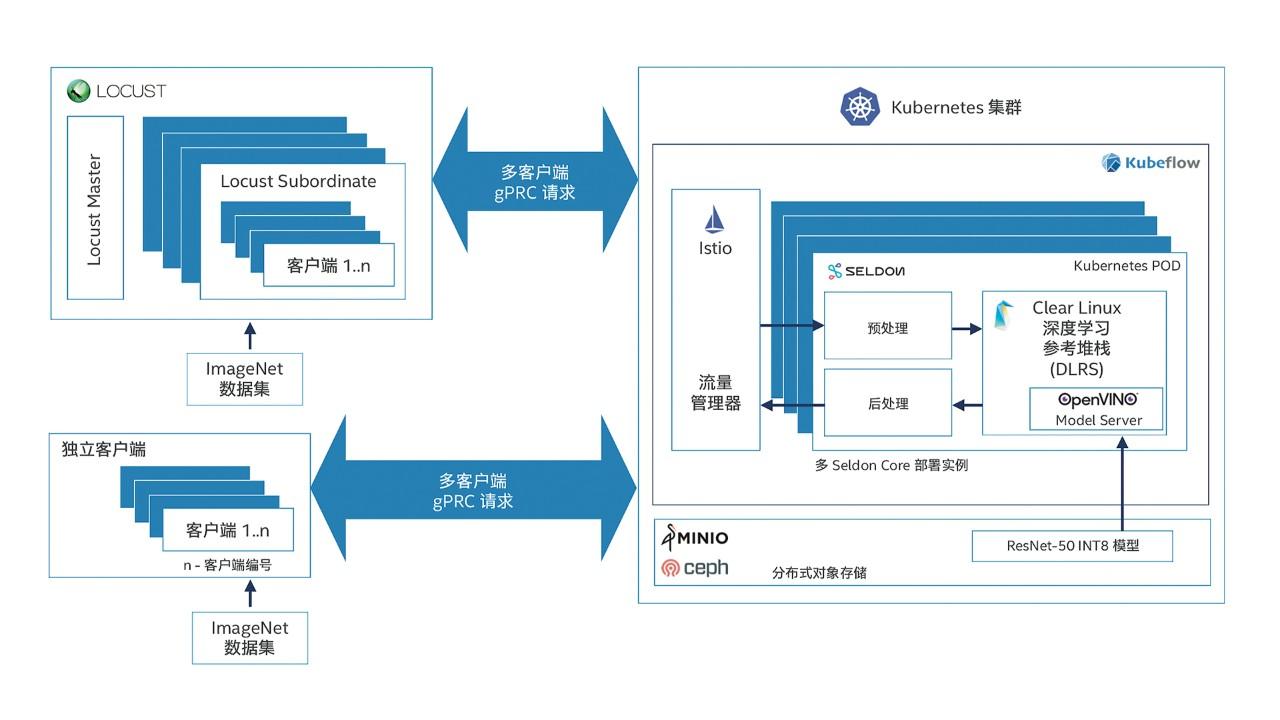
圖 2. 在面向人工(gōng)智能推理的英特爾® 精選解決方案上進行的真實場景基準測試架構圖
 czk634@gzyuqiang.com
czk634@gzyuqiang.com
 134-2756-1409 158-7654-7788
134-2756-1409 158-7654-7788
 廣州市天河區石牌西路8号1806房
廣州市天河區石牌西路8号1806房



